Why Use Version Control?
This is partly based on some content from my book Git In Practice.
You may not be familiar with version control concepts or why version control systems are useful for managing changes to text. Let’s start off by asking why you should use version control.
A common problem when dealing with information stored on a computer is handling changes. For example, after adding, modifying or deleting text you may want to undo that action (and perhaps redo it later). At the simplest level this might be done by clicking undo in a text editor (which reverts a previous action); after new words are added it may be necessary to undo these changes by pressing undo repeatedly until you return to the desired previous state.
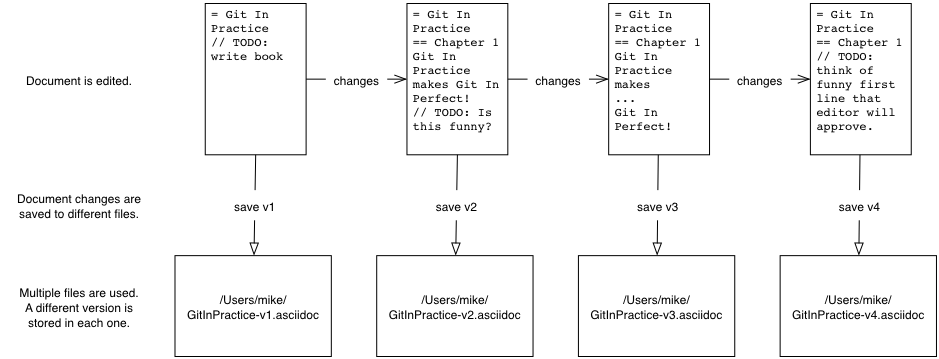
A naïve method for handling multiple file versions is often simply creating duplicate files with differing filenames and contents (Important Document V4 FINAL FINAL.doc may sound sadly familiar).
At a more advanced level you may be sharing a document with other people and, rather than just undoing and redoing changes, wish to know who made a change, why they made it, when they made it, what the change was and perhaps even store multiple versions of the document in parallel. A version control system (such as Git) allows all these operations and more.
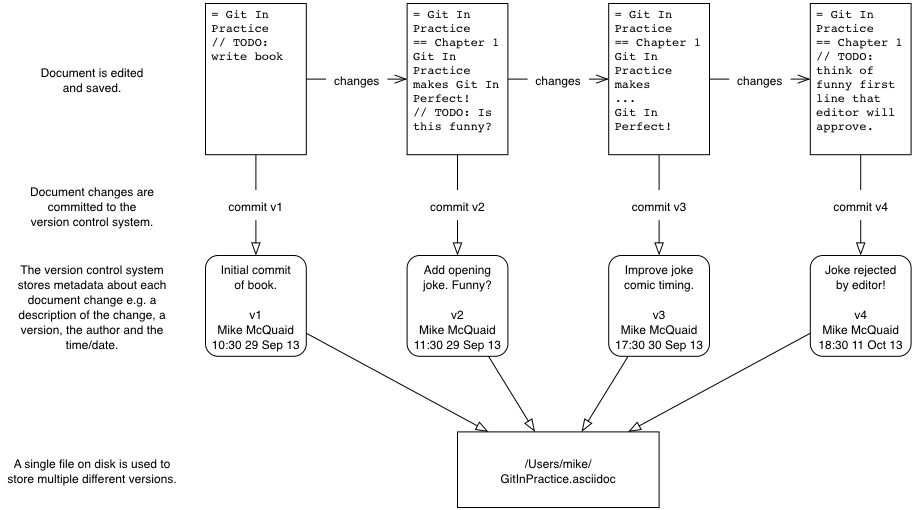
In a version control system instead of just saving a document after your changes have been made you would commit it. This involves a save-like operation commanding the version control system to store this particular version and specifying a message stating the reason for their change or what it accomplishes. When another commit is made then the previous version would remain in history where its changes can be examined at a later time. Version control systems can therefore solve the problem of reviewing and retrieving previous changes and allow single files to be used rather than duplicated.
When editing a file in a version control system you will always edit/save/commit the same file on disk. It will not move location either manually or automatically (unless you wish to rename it, of course). When you wish to access previous versions of the file you can either view them through the version control system or restore the file on disk to a previous version. This allows you to see exactly what may have changed between versions. When using multiple files you would have to manually compare each of the files to see differences and keep track of multiple files on your disk.
Version control systems work by maintaining a list of changes to files over time. Each time a file is modified and committed the new version of the file is stored in the repository; a centralized location where the version control system stores files for a particular project. Each commit corresponds to a particular version and stores references to the previously made commit, a commit message describing the changes made in this commit, the time it was made, who made it and the contents of the files at this point. The files’ state from a commit can be compared to a previous version and the difference between the versions’ files (known as diffs) can be queried.

After adding new changes to versioned files you will create new commits containing these changes and commit the changes to the repository. At a later point you can checkout different versions of files. This allows you to have confidence that, no matter what you may add, modify or delete, all committed versions of your files will remain in the version control system if you need to check their contents later.
Programmers spend most of their jobs editing text. This text is typically source code which will be interpreted by a computer to perform some task but could also be software configuration files, documentation or emails. As they typically work on independent units of work while in larger teams and can be distributed by time or geography it’s important that they communicate explicitly to other programmers why a particular change was made. Additionally programmers inevitably write software which contains bugs. When trying to work out why a bug occurred it’s useful to see what changes were made, by whom and for what reason. Often programmers will need to fix bugs in sections of code they did not create so being able to record and recall the intent of the code’s author at a later point can help understand what may have caused a bug. These reasons are multiplied by the fact that programmers typically work with huge numbers of source files. Given these reasons it should be clear why most programming projects use version control systems to manage their source code.
When creating computer software it’s also common to release new versions of the software. New versions are generally released when bugs are fixed and/or when new features have been implemented. Sometimes a team may be developing a new feature but need to provide a new version with a bug fixed before the new feature is ready. Two branches could be used to work on the bug fix independently of the new feature. This would allow work on the bug fix and the new feature to occur in parallel. These branches could be later merged which would include all the changes made in one to be included into the other.
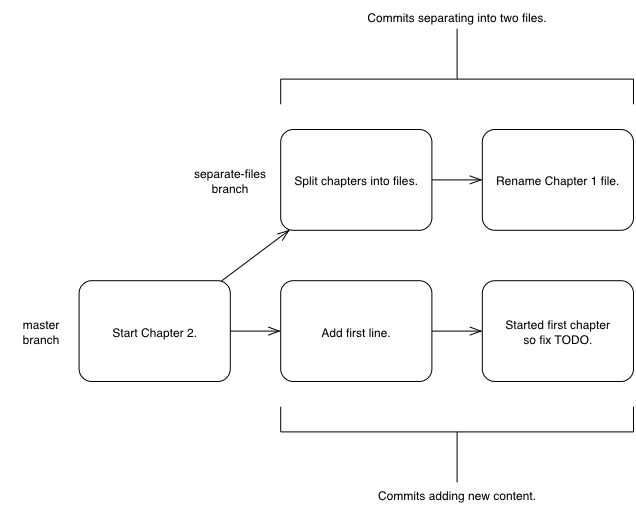
Changes, commits, history, a repository, diffs and branches are all typically provided by version control systems (such as Git). These features enable workflows where changes are logged for future reference, work can be be done in parallel and previous versions of files are kept. Hopefully this provides you with a basic understanding of why version control systems are useful.
