Ruby on (Guard)Rails
I’ve worked on a few Ruby apps in my career at varying scales:
- Homebrew (2009-present): created 2009, I started working on it ~5 months in and was maintainer #3.
- AllTrails (2012-2013): created 2010, I was employee ~#8 and worked on their (smallish) Ruby on Rails application for ~1.5 years.
- GitHub (2013-2023): created 2007, I was employee ~#232 and worked on their (huge) Ruby on Rails application for ~10 years.
- Workbrew (2023-present): I cofounded Workbrew in 2023 and built the Workbrew Console Ruby on Rails application from scratch.
Over all of these Ruby codebases, there’s been a consistent theme:
- Ruby is great for moving fast
- Ruby is great for breaking things
What do I mean by “breaking things”?
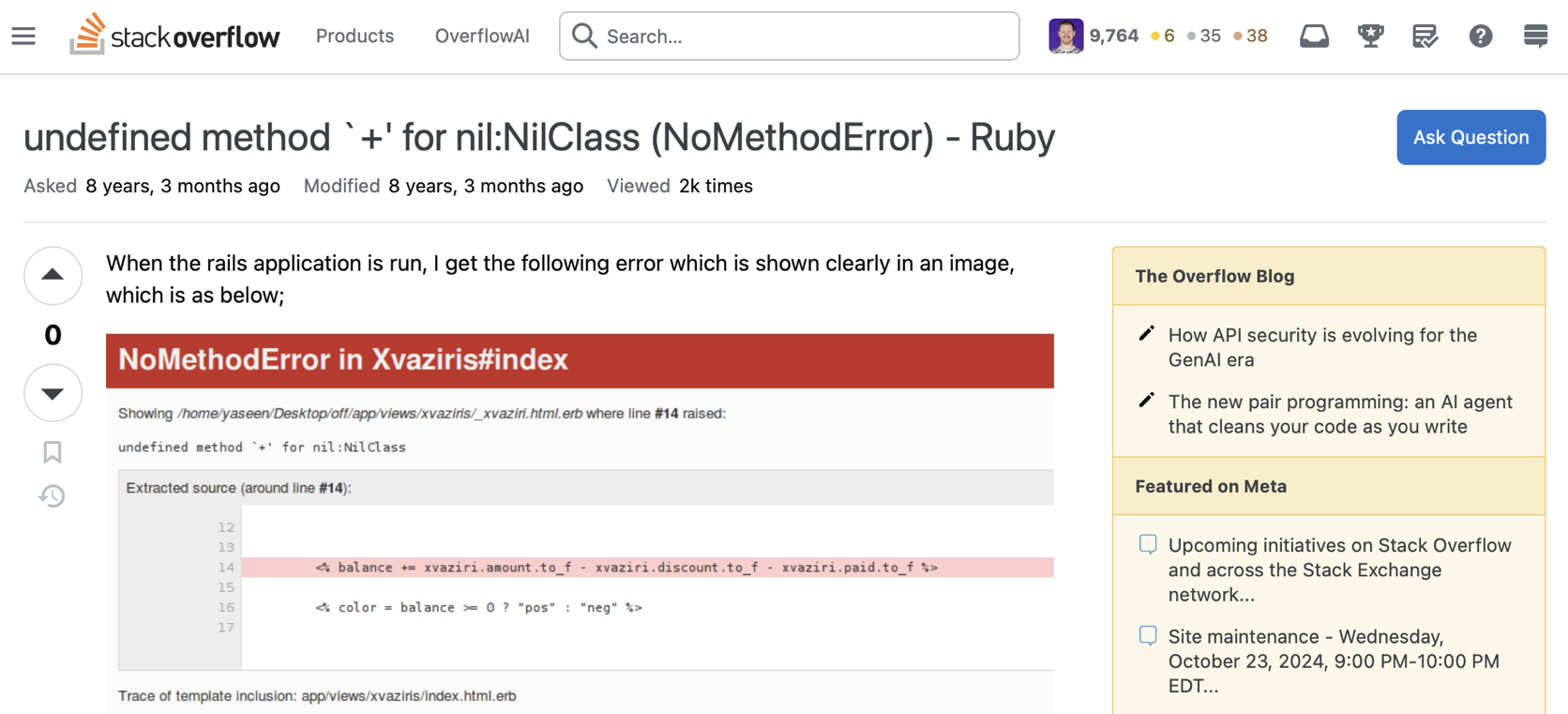
If you’ve been a Ruby developer for any non-trivial amount of time, you’ve lost a non-trivial amount of your soul through the number of times you’ve seen this error. If you’ve worked with a reasonably strict compiled language (e.g. Go, Rust, C++, etc.) this sort of issue would be caught by the compiler and never make it into production. The Ruby interpreter, however, makes it very hard to actually catch these errors at runtime (so they often do make it into production).
This is when, of course, you’ll jump in with “well, of course you just need to…” but: chill, we’ll get to that. I’m setting the scene for:
🤨 The Solution
The solution to these problems is simple, just …
Actually, no, the solution is never simple and, like almost anything in engineering: it depends entirely on what you’re optimising for.
What I’m optimising for (in descending priority):
- 👩💻 developer happiness: well, this is why we’re using Ruby. Ruby is optimised for developer happiness and productivity. There’s a reason many Ruby developers love it and have stuck with it even when it is no longer “cool”. Also, we need to keep developers happy because otherwise they’ll all quit and I’ll have to do it all myself. That said, there’s more we can do here (and I’ll get to that).
- 🕺 customer/user happiness: they don’t care about Ruby or developers being happy. They care about having software that works. This means software where bugs are caught by the developers (or their tools) and not by customers/users. This means bugs that are found by customers/users are fixed quickly.
- 🚄 velocity/quality balance: this is hard. It requires accepting that, to ship fast, there will be bugs. Attempting to ship with zero bugs means shipping incredibly slowly (or not at all). Prioritising only velocity means sloppy hacks, lots of customer/user bugs and quickly ramping up tech debt.
- 🤖 robot pedantry, human empathy: check out the post on this topic. TL;DR: you want to try to automate everything that doesn’t benefit from the human touch.
The Specifics
Ok, enough about principles, what about specifics?
👮♀️ linters
I define “linters” as anything that’s going to help catch issues in either local development or automated test environments. They are good at screaming at you so humans don’t have to.
- 👮♀️
rubocop: the best Ruby linter. I generally try to enable as much as possible in Rubocop and disable rules locally when necessary. - 🪴
erb_lint: like Rubocop, but for ERB. Helps keep your view templates a bit more consistent. - 💐
better_html: helps keep your HTML a bit more consistent through development-time checks. - 🖖
prosopite: avoids N+1 queries in development and test environments. - 🪪
licensed: ensures that all of your dependencies are licensed correctly. - 🤖
actionlint: ensures that your GitHub Actions workflows are correct. - 📇
eslint: when you inevitably have to write some JavaScript: lint that too.
I add these linters to my Gemfile with something like this:
group :development do
gem "better_html"
gem "erb_lint"
gem "licensed"
gem "rubocop-capybara"
gem "rubocop-performance"
gem "rubocop-rails"
gem "rubocop-rspec"
gem "rubocop-rspec_rails"
end
If you want to enable/disable more Rubocop rules, remember to do something like this:
require:
- rubocop-performance
- rubocop-rails
- rubocop-rspec
- rubocop-rspec_rails
- rubocop-capybara
AllCops:
TargetRubyVersion: 3.3
ActiveSupportExtensionsEnabled: true
NewCops: enable
EnabledByDefault: true
Layout:
Exclude:
- "db/migrate/*.rb"
Note, this will almost certainly enable things you don’t want.
That’s fine, disable them manually.
Here you can see we’ve disabled all Layout cops on database migrations (as they are generated by Rails).
My approach for using linters in Homebrew/Workbrew/the parts of GitHub where I had enough influence was:
- enable all linters/rules
- adjust the linter/rule configuration to better match the existing code style
- disable rules that you fundamentally disagree with
- use safe autocorrects to get everything consistent with minimal/zero review
- use unsafe autocorrects and manual corrections to fix up the rest with careful review and testing
When disabling linters, consider doing so on a per-line basis when possible:
# Bulk create BrewCommandRuns for each Device.
# Since there are no callbacks or validations on
# BrewCommandRun, we can safely use insert_all!
#
# rubocop:disable Rails/SkipsModelValidations
BrewCommandRun.insert_all!(new_brew_command_runs)
# rubocop:enable Rails/SkipsModelValidations
I also always recommend a comment explaining why you’re disabling the linter in this particular case.
🧪 tests
I define “tests” as anything that requires the developer to actually write additional, non-production code to catch problems. In my opinion, you want as few of these as you can to maximally exercise your codebase.
- 🧪
rspec: the Ruby testing framework used by most Ruby projects I’ve worked on. Minitest is fine, too. - 🙈
simplecov: the standard Ruby code coverage tool. Integrates with other tools (like CodeCov) and allows you to enforce code coverage. - 🎭
playwright: dramatically better than Selenium for Rails system tests with JavaScript. If you haven’t already read Justin Searls’ post explaining why you should use Playwright: go do so now. - 📼
vcr: record and replay HTTP requests. Nicer than mocking because they test actual requests. Nicer than calling out to external services because they are less flaky and work offline. - 🪂
parallel_tests: run your tests in parallel. You’ll almost certainly get a huge speed-up on your multi-core local development machine. - 📐 CodeCov: integrates with SimpleCov and allows you to enforce and view code coverage. Particularly nice to have it e.g. comment inline on PRs with code that wasn’t covered.
- 🤖 GitHub Actions: run your tests and any other automation for (mostly) free on GitHub.
I love it because I always try to test and automate as much as possible.
Check out Homebrew’s
sponsors-maintainers-man-completions.ymlfor an example of a complex GitHub Actions workflow that opens pull requests to updates files. Here’s a recent automated pull request updating GitHub Sponsors in Homebrew’sREADME.md.
I add these tests to my Gemfile with something like this:
group :test do
gem "capybara-playwright-driver"
gem "parallel_tests"
gem "rspec-github"
gem "rspec-rails"
gem "rspec-sorbet"
gem "simplecov"
gem "simplecov-cobertura"
gem "vcr"
end
In Workbrew, running our tests looks like this:
$ bin/parallel_rspec
Using recorded test runtime
10 processes for 80 specs, ~ 8 specs per process
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
....................................................................
......................
Coverage report generated to /Users/mike/Workbrew/console/coverage.
Line Coverage: 100.0% (6371 / 6371)
Branch Coverage: 89.6% (1240 / 1384)
Took 15 seconds
I’m sure it’ll get slower over time but: it’s nice and fast just now and it’s at 100% line coverage.
There has been (and will continue to be) many arguments over line coverage and what you should aim for. I don’t really care enough to get involved in this argument but I will state that working on a codebase with (required) 100% line coverage is magical. It forces you to write tests that actually cover the code. It forces you to remove dead code (either that’s no longer used or cannot actually be reached by a user). It encourages you to lean into a type system (more on that, later).
🖥️ monitoring
I define “monitoring” as anything that’s going to help catch issues in production environments.
- 💂♀️ Sentry (or your error/performance monitoring tool of choice): catches errors and performance issues in production.
- 🪡 Logtail (or your logging tool of choice): logs everything to an easily queryable location for analysis and debugging.
- 🥞 Better Stack (or your alerting/monitoring/on-call tool of choice): alerts you, waking you up if needed, when things are broken.
I’m less passionate about these specific tools than others. They are all paid products with free tiers. It doesn’t really matter which ones you use, as long as you’re using something.
I add this monitoring to my Gemfile with something like this:
group :production do
gem "sentry-rails"
gem "logtail-rails"
end
🍧 types
Well, in Ruby, this means “pick a type system”. My type system of choice is Sorbet. I’ve used this at GitHub, Homebrew and Workbrew and it works great for all cases. Note that it was incrementally adopted on both Homebrew and GitHub.
I add Sorbet to my Gemfile with something like this:
gem "sorbet-runtime"
group :development do
gem "rubocop-sorbet"
gem "sorbet"
gem "tapioca"
end
group :test do
gem "rspec-sorbet"
end
A Rails view component using Sorbet in strict mode might look like this:
class AvatarComponent < ViewComponent::Base
sig { params(user: User).void }
def initialize(user:)
super
@user = user
end
sig { returns(User) }
attr_reader :user
sig { returns(String) }
def src
if user.github_id.present?
"https://avatars.githubusercontent.com/u/#{user.github_id}"
else
...
end
end
In this case, we don’t need to check the types or nil of user because we know from Sorbet it will always be a non-nil User.
This means, at both runtime and whenever we run bin/srb tc (done in the VSCode extension and in GitHub Actions), we’ll catch any type issues.
These are fatal in development/test environments.
In the production environment, they are non-fatal but reported to Sentry.
Note: Sorbet will take a bit of getting used to.
To get the full benefits, you’ll need to change the way that you write Ruby and “lean into the type system”.
This means preferring e.g. raising exceptions over raising nil (or similar) and using T.nilable types.
It may also include not using certain Ruby/Rails methods/features or adjusting your typical code style.
You may hate it for this at first (I and many others did) but: stick with it.
It’s worth it for the sheer number of errors that you’ll never encounter in production again.
It’ll also make it easier for you to write fewer tests.
TL;DR: if you use Sorbet in this way: you will essentially never see another nil:NilClass (NoMethodError) error in production again.
That said, if you’re on a single-developer, non-critical project, have been writing for a really long time and would rather die than change how you do so: don’t use Sorbet.
😌 Ad Hominem
Well, I hear you cry, “that’s very easy for you to say, you’re working on a greenfield project with no legacy code”. Yes, that’s true, it does make things easier.
That said, I also worked on large, legacy codebases like GitHub and Homebrew that, when I started, were doing very few of these things and now are doing many of them. I can’t take credit for most of that but I can promise you that adopting these things was easier than you would expect. Most of these tools are built with incrementalism in mind.
Perfect is the enemy of good. Better linting/testing/monitoring and/or types in a single file is better than none.
🤥 Cheating
You may feel like the above sounds overwhelming and oppressive. It’s not. Cheating is fine. Set yourself strict guardrails and then cheat all you want to comply with them. You’ll still end up with dramatically better code and it’ll make you, your team and your customers/users happier. The key to success is knowing when to break your own rules. Just don’t tell the robots that.
